Can Health
Care Information Technology
Adapt?
Prepared for
Veterans Health
Administration
Department of Veterans
Affairs
Tom Munnecke
Science Applications
International Corporation
(858) 756 4218
Version 1.0
Available at http://www.munnecke.com/papers/D23.doc
Complexity, Information, and our Ways of Understanding
How Adaptive Have Our
Systems Been?
Lessons Learned from Y2K
Issue
The Transition to Genomics
and Proteomics
Transition from Biological
to the Genetic Era of Medicine
Science and Biological
Medicine
Complexity, Information, and our Ways of Understanding
Imagine a scientist
trying to understand a symphony played by an orchestra. The scientist might start by putting a
microphone in the audience, recording the sound waves as they come from the
orchestra. These would be digitalized
into bit streams to be analyzed by a computer to look for patterns. When the first attempt failed, the scientist
might increase the sensitivity of the microphone and increase the sampling
rate, generating even more data. When
this attempt failed, the scientist might add 15 more microphones in different
sampling positions, hoping to finally get enough data to understand the music.
If the scientist
wandered up on stage, however, the score used by the conductor would be
obvious. The notes of the symphony could be represented with
kilobytes of information. The gigabytes of data
collected by the array of microphones made it difficult to understand what was
obvious and simply represented on the musical notation.
The conductor’s score
represented a language which was interpreted to become the symphony. The technique of recording
all the emanations of the instruments as discrete events and digital
“snapshots” lead to an ever-increasing labyrinth of complexity. More data created more complexity. Having a musical language, however, creates a
simpler way of representing what otherwise would be an enormously complex
undertaking.
Our current situation in health care
can be likened to that scientist in the auditorium. We are already
receiving an overwhelming array of data and
information, and we know that with the advent of
genetically based medicine this flow will increase dramatically,
perhaps by orders of magnitude. This information may
be of a fundamentally different nature than what we are receiving today. Our current models of
understanding health and medicine may undergo fundamental
revisions.
Perhaps this new technology will
appear gradually, merely being minor additions to the formulary and some
additional lab tests. Current physicians
will be able to study papers and take some CME courses to understand it. Perhaps some new specialties will arise
within the existing framework of health care delivery.
On the other hand, these changes may
have far greater scope than is currently imagined. Issues of privacy, politics, fear of the
unknown, and media frenzies may swamp scientific evidence and
clinical research. New knowledge may
emerge from the lab and be driven by direct to consumer
marketing activities faster than our current knowledge system, to the extent
that it exists, can assimilate them.
Efforts to automate the medical
record go back at least 30 years, yet there is no
wide-spread success.
Clinical knowledge can take 17
years to disseminate for general use. In today’s world of “Internet time” these
numbers are amazingly long. Medicine and our health care system stands on
the brink of waves of rapid change, yet its information and knowledge
infrastructure stands as one of the longest running failures in the information
technology industry.
Like our symphony scientists getting
overwhelmed by the data generated by their array of microphones, medicine and
health care are being overwhelmed by inappropriate
information and knowledge structures. Our way out of the exploding complexity we
face is through smarter information
structures, and perhaps wandering out of the audience to discover a
higher level language – a “score” which simplifies our quest.
Waves of Accelerating Change
There
is a huge gap between technology and our ability to apply it in health care,
much of which reduces to our ability to handle information:
“Health
care today is characterized by more to know, more to manage, more to watch,
more to do, and more people involved in doing it than at any time in the
nation’s history. Our current methods of
organizing and delivering care are unable to meet the expectations of patients
and their families because the science and technologies involved in health care
– the knowledge, skills, care interventions, devices, and drugs – have advanced
more rapidly than our ability to deliver them safely, effectively, and
efficiently.[1]
We
can expect these technological changes to continue at an increasing rate from
many different directions. Technology in
general is accelerating:
“[We are approaching] the "perfect
storm" of the converging exponentials of bio-X, nanotech, and information
technologies/telecommunications. They will cause more change in less time than
anything humankind has ever witnessed.”[2]
Specific advances in
proteomics will have dramatic effects on clinical systems:
“The
next technological leap will be the application of proteomic technologies to
the bedside…This will directly
change clinical practice by affecting critical elements of care and management. Outcomes may include early detection of
disease using proteomic patterns of body fluid samples, diagnosis based on
proteomic signatures as a complement to histopathology, individualized
selection of therapeutic combinations that best target the entire
disease-specific protein network, real-time assessment of
therapeutic efficacy and toxicity, and rational modulation of therapy based on
changes in the diseased protein network.”[3]
Our understanding of
interactions between drugs and genotype-specific activities will also trigger
tremendous changes in health care:
Pharmacogenomics requires the integration and
analysis of genomic, molecular, cellular, and clinical data, and thus offers a remarkable set
of challenges to biomedical informatics. These include infrastructural
challenges such as the creation of data models and data bases for storing this data, the
integration of these data with external databases, the extraction of information from natural language
text, and the protection of databases with sensitive information. There are also
scientific challenge in creating tools to support gene expression analysis, three-dimensional
structural analysis, and comparative genomic analysis.[4]
How
Adaptive Have Our Systems Been?
Given these dramatic
and accelerating forces on our health care system, it is instructive to look at
how well the current system adapts to change.
Past history does not indicate a particularly adaptive
response to even simple issues:
·
An average of 17 years
is required for new knowledge generated by randomized controlled trials to be
incorporated into clinical practice.[5]
·
Changing our computer systems to deal with the Year 2000 (Y2K) problem cost the
·
The feedback loop between treatment and its
effectiveness has not always worked well:
“By
the time Moniz and Hess shared the Nobel Prize in 1949, [for inventing the
frontal lobotomy] thousands of lobotomies were being performed every year. Yet by the end of the 1950s, careful studies
revealed what had somehow escaped the notice of many practicing physicians for
two decades: the procedure severely damaged the mental and emotional lives of
the men and women who underwent it.
“Lobotomized” became a popular synonym for “zombie,” and the number of
lobotomies being performed dropped to near zero.”[7]
·
Despite 30 years of
aggressive attempts to create an electronic medical
record, this goal is still elusive. For example, in 1991, the Institute of
Medicine’s Committee on Improving the Patient Record set a goal of making the
computer-based patient record a standard technology in health care by 2001.[8] Given
the pressures of cost cutting, continuous changes in the industry, and
increasingly complex issues relating to privacy, liability, bioterrorism, and
genetic information security, it is likely
that our ability to achieve this
goal is diminishing, rather than increasing. One reason for this continued failure is the
brittleness of the technology we are attempting to use. It is simply not adaptive enough for the
task. A Critical Time to Act
Lessons Learned from Y2K Issue
The calendar
change
to the new millennium triggered a Y2K problem of immense magnitude. Some pPredictions
ofed a global recession as
computer systems, electronic funds transfers, and transportation systems shut
down did not occur. The fact
that the world
could bewas brought to the brink
of such catastropheYet the Y2K problem
was a relatively minor change to the system:s is
remarkable due tofor the following reasonsissues:
1.
1.
The root problem was trivial – expanding a date field from two
to four digits was something that could be
accomplished by even the most inexperiencednovice programmers. The problem was easily stated and recognized
2.
2.
We had perfect foreknowledge of the problem. The fact
that there would be a year 2000 was always known.
The arrival of
3.
3.
The problem was reversible. With certain
exceptions (for example, the safety of a factory control system), problems
which may have been encountered during the changeover would have triggered
delays in operation. For example, Eeven if an airline reservation system
failed, for
example, service could be eventually restored and the system could returned
to normal.
4.
It
illustrated the network effect. The problem did not only exist in isolated
computer systems, but also in all of the interconnections between them. Electronic funds transfer systems, for
example, connected the world’s banking systems
together, and a failure in a critical component could have cascaded into other
systems. What started out as isolated,
enterprise-only applications had become globally connected.
Nevertheless, avoiding
the this
problemY2K problem cost the United States an
estimated $100 billion and the federal government $8.5 billion to avoid
the Y2K problem.
The Transition to
Genomics and Proteomics
The world is
facingnow faces another mega-issue, based on our rapidly
increasing understanding
knowledge of DNAgenomicsAs w. We are just beginning to unraveling the complex mysteries of the gene, . O our understanding of genomics and
proteomics could
will
have
dramatic effects on our personal health and our health care
system. Compared to what we went through with Y2K:This problem has far greatert immediate and long
term consequences:
1.
1.
The root problem issue is
immense. The field of bBioinformatics
is one of the most challenging computer science problems today,
pushing the state of the art in computer science, supercomputing,
mathematics, biology, and complexity sciences.
It
is pushing the technological limits of supercomputing, database storage,
knowledge management, and standardization.Notions of privacy
will extend beyond individuals to familial membersrelatives, not just individuals.
2.
It opens up entirely
new problems of privacy. Notions of privacy
will extend beyond individuals to entire families. Relatives will become trustees of each
other’s genetic information. Information which was
not sensitive in one era of knowledge may become highly sensitive with future
discoveries. Genotype testing could discover that a person is
“difficult to treat” or “more expensive to treat” which could impair their
future ability to get health insurance, a job, or other adverse events. Furthermore, genetic samples released earlier
could be reinterpreted with new knowledge, so that an informed consent at one
time could lead to future negative effects in the future, beyond the
expectations of the patient at the time of signing. Thus, what is not sensitive today could become
very sensitive tomorrow. New social questions and ethical problems will emerge regarding race and
ethnicity.[9]. – what
if a genetic privacy mechanism detects a biological father different from that
person’s named father, for example?
3.
2.
We don’t know what we don’t know. We can only expect
surprises from our research and discoveries. How discoveries will affect with existingcurrent
medical practices,
knowledge, and the public is unpredictable. “It is
not entirely clear how many of the 35,000 genes assigned in the rough
draft of the human genome are relevant to drug response (or even how to define ‘relevance’)”[10]
4.
The tempo
of knowledge creation is increasing. Given
that anIt now takes an average of 17 years is required for new medical knowledge generated
from randomized controlled trials to be completely
incorporated into clinical practice. In the future,
it is likely that new information will be created, and possibly
madebecome obsolete in this
time, by the time it is put into practice.
The Eeven what we think we
do “know” may not be true, given the
paradoxical nature of self-referential
systems such as DNA..
5.
3.
The problemBioterrorism has
entered the picture. may be irreversible.
Changing
the evolution of the humans
species, for example, is not something which can could be
subjected to clinical trials. New pathogens may might
be created, either accidentally
orperhaps by terrorists, which, once
released, cannot be withdrawn.. Warfare has always
attacked the means of a society’s production; the
more productive the genomic revolution becomes, the more attractive it becomes
for nefarious purposes.
6.
4.
The problem is continuous. While the Y2K problem climaxed ended on
a specific date, this problemthe coming changes in
medicine will may be continuousaffect
current and future generations on a continuingous
basis. Risks to future generations need to be balanced
against benefits to the current one.There may not be a
specific date on which will trigger action.
7.
5.
Our current scientific method may not be powerful enough.
Current notions of causality, repeatability, and objectivity in scientific
experimentation may not be capable of expressing cascades, singularities, and
self-referential processes inherent in genetic and complex adaptive systems. At
some point, the reductionistic model of
scientific research will collide with the paradoxes of self-reference inherent
in understanding DNA. Biological
notions of causal effects, “root cause analysis,”
and other deterministic approaches may
not be able to cope with feedback systems, parallelism,
adaptation, and evolutionary processes.
Yet we have little or no information infrastructure to
record or understand such effects.
8.
Basic
notions of
health and disease may
change. In the same way that
it is impossible to create a one-to-one map between Chinese traditional medical
concepts and Western biological allopathic medical models, it
is likely that our genetic understanding
of medicine will create new ways
of understanding health and disease which cannot be mapped one-to-one
to our current understanding of disease.
We may discover new cascades, networks, and metaphors
which are simply beyond the ability of our current information systems to
express. The limited
expressiveness of our current systems may in fact limit our ability to discover
these effects. We may find
it necessary to represent notions of adaptation, evolution, learning, and
feedback on the individual level, or even smaller components of an individual. We may find a need to collect and treat
families, communities, or collections of individuals with a common genotype,
blending scales of intervention in ways not understood by current information
systems.
1.
9.
6.
Network effects may dominate. The World Wide Web has
exploded into a leading global communications medium in just a decade,
exploiting the network effect of connectivity. Simple initial conditions
can be amplified to create a huge cumulative effect. This may create
emergent properties which are not predictable from the outset, in the same way
that it would have been impossible to predict the effects of the three initial
web concepts of URL, HTTP, and HTML on global communications and
commerce. We have little understanding of how cascades
operate, yet this is the core of the genetic process. We are connecting society,
ourselves, our knowledge, and our health care
systems in entirely new ways and subjecting
them all to the network effect. For
example, all of our scientific knowledge about Cipro could not have predicted its
emergence in the Anthrax scare in September, 2001, and its effect on microbial
resistance.
10.
The complexity of the
current health care system is already near a breaking point. “The
The changes mandated
to our information infrastructure cannot be accommodated as
simply as adding a few characters to a field, as was done with Y2K. It is problematical whether they can even be
accommodated within the current information systems technology we use. Accommodating these changes will require some
fundamental rethinking of health care system, its science, and the media by
which medical knowledge is communicated.
The Need for Adaptability
Adaptability
of our information systems can be seen to be a core need of our information
systems, particularly if it is viewed in a broader perspective:
|
Adaptability over |
Equates to |
|
Users |
Security |
|
Patients |
Privacy |
|
Time |
Maintenance |
|
Sites |
Portability |
|
Hardware |
Hardware |
|
Data bases |
Data independence |
|
Medical Model |
Transition from
biological to genetic models of medicine |
Brittleness
in any of the above areas tends to indicate brittleness in the other
categories. Viewed from this perspective,
CIO’s budgets are largely controlled today by the cost of adaptation. Prospects for future activities will
increasingly be controlled by concerns of adaptation: privacy and security
being “sleeper” issues which are increasingly becoming drivers in both medicine
and general information concerns.
Transition from
Biological to the Genetic Era of Medicine
We can look at three great waves of
modern medicine and health:
1.
Sanitary – understanding
germs, the role of public health in creating sanitary sewagage systems and
water supplies.
2.
Biological – understanding the
components of living things such as cells, organs, and biochemical
processes. Understanding diseases and
symptoms of failure of these components, and applying scientific
experimentation to discover their treatment and cure. The success story of allopathic medicine.
3.
Genetic – understanding
health and disease based on our understanding of the basic genetic makeup of
living things as expressed in DNA codes.
This phase is just beginning; we are just now beginning to get the raw
data with which to begin our deeper understanding of the genetic basis of
health.
|
Medical
Era |
Scale |
Key
Theories |
Validation
of Theory |
|
Sanitary |
Cities, communities |
Germs, antisepsis |
Population
statistics |
|
Biological |
Individuals, organs |
Allopathic medicine,
evidence-based medicine |
Experimentation,
clinical trials, outcomes
assessment |
|
Genetic |
Genes, base pairs |
DNA replication,
genomics, proteomics |
??? |
Science
and Biological
Medicine
Claude Bernard was one of the early thought leaders
in bringing about the biological age of medicine. In the late 1800’s there was considerable
turmoil in thinking about living things, including the
groundbreaking theory of evolution
by Charles Darwin. There were those who
thought that life was caused by an élan vital, a mysterious life force which
could be contacted in the spirit world through séances. Superstition and religious
beliefs
clashed with science. The scientific method was
a crucial ally in this effort. It is interesting, however, to note that 150
years after the introduction of the scientific
method in medicine that we are still
calling for “evidence-based
medicine.”
Bernard, faced with
trying to create experimentally provable medical knowledge, used scientific
laws and methods for proof:
“In
living bodies, as in organic bodies, laws are immutable, and the phenomena
governed by these laws are bound to be the conditions on which they exist, by a
necessary and absolute determinism…if they [experimenters] are thoroughly
imbued with the truth of this principle, they will exclude all supernatural
intervention from their expectations; they will have unshaken faith in the idea that
fixed laws govern biological science; and at the same time they will have a
reliable criterion for judging the often variable and contradictory appearance
of vital phenomena…for the facts cannot contradict one to another, they can
only be indeterminate... Facts never
exclude one another, they are simply explained by differences in the conditions
in which they were born. [italics added]”[13]
It is interesting that Bernard is countering the
vitalists’ belief system with his own admonition of “unshakable faith” in fixed
laws of biology. Would research
conducted under principles of “absolute faith” ever be capable of refuting the
belief system of those who professed it?
He was replacing faith-based vitalism with faith-based experimental
medicine.
A fundamental tenet of Bernard’s scientific faith was
to slice the relationship between the observer and the subject. “Experiment becomes the mediator between the
objective and the subjective, that is to say, between the man of science and
the phenomena which surround him.”[14]
Subsequent discoveries by scientists
and mathematicians, however, have made discoveries which undercut Bernard’s
“unshakable faith.”
Self-Referential
Systems
The line between subject and observer is not as
distinct as Bernard would have it. DNA,
for example, is a self-referential system.
DNA encodes a mechanism which interprets a code which constructs the
mechanism. Is DNA the subject or the
object of an experiment? If we “slice”
the experimental process to assume that it is one, how do we know that we are
not simultaneously changing the other? This is a little like looking into a mirror
which looks into a parallel mirror, creating perfectly parallel
reflections. If we stick our face
between them to see what we see, we see the injection of our face in the
mirrors, not the mirrors without our observing face. This leads to paradoxical situations which
can only be “objectified” by arbitrarily cutting off the self-referential
loop. We just define the observation to
be a specific iteration of the loop, and are then able to carry on with a
“consistent” theory of how things work.
Mathematician Kurt
Goedel created a formal mathematical model of this problem in the mid 20th
century,
called Goedel’s Incompleteness Theorem.
Roughly stated, any language capable of referring to itself is capable
of expressions which can neither be proven true or false within that
language. For
example, the sentence, “This sentence is false.” is a paradox which
cannot be proved true or false within the language in which the sentence is
written. Like the DNA code which creates
both the machine to interpret the code and the code itself, we are dealing with
the paradox of self reference.
These paradoxes can be
resolved by creating higher level language, one which “looks down” on the lower
level language which resolves the self-referential statement to be either true
or false. Users of that language can then go about their business of
maintaining consistency and truth within that language.
However, this only
bumps up the problem one level. If this
higher level language is self referential, then it can contain a self-referential statement, which can only be
proven true by yet another, higher level language. This leads to an infinite regress of higher
level language.
If DNA is the language
of life, then it is tied to this infinite regress. This regress can be ignored to some extent,
but a full understanding
of DNA’s
meaning will eventually
revolve around our ability to deal
with the paradox of self reference. It
is doubtful that Bernard’s “unshakable faith” in objectivity, which served us
so well in the biological era of medicine, will stand unshaken as we unravel
the meaning of DNA and life. In fact,
probing the paradoxes of self-reference and object/subject “observation” may
well be the path towards understanding. Sooner or later, our information
infrastructures will have to deal
with issues of self-reference, feedback, and recursion. Information
systems to date have dealt with this problem by simply ignoring them. Representing and understanding adaptive,
learning, evolving systems is very difficult, yet it
is the key towards a richer information infrastructure. If
we are ever to discover the “score” in health care and medicine, it is likely
to be closely tied to our understanding of the cascades of effects caused by
DNA.
Fractals
Mandelbrot
introduced the notion of fractal
geometry in the 1970’s. Fractal
objects do not neatly fit into “normal” dimensions.
The scale at which we examine a fractal object affects the measurement.
For example, suppose
we want to
tie a rope around an island, touching the entire
shoreline. How much rope would we need? This would seem to be a simple question, but
what if the island is highly irregular, with deep bays and promontories?
Do we wrap the rope
from one promontory to the next, or have it follow the coast line. If we follow the coastline, do we follow
smaller indentations? If we follow them,
do we follow river inlets? If so, do we
follow the branches of the rivers into streams?
If we follow streams, do we follow individual rocks? If we make the rope smaller, so that it is a
string, do we follow smaller rocks? If
we make the string the thickness of a hair, do we follow even smaller pebbles?
If we are dealing with
a fractal or self-similar object,
the question of length requires that we also
specify the scale at
which we examine it. A non-fractal
object, such as a house, does not behave this way. The more we measure the outside of a smooth
house, for example, the more accurately we converge on the ‘true’ circumference. We have well-developed statistical techniques
to deal with measurement error and normal Gaussian
distributions. We don’t
have well developed techniques to deal with fractal
objects. Yet
examples of self-similar objects in medicine abound, such as dendrites of
neurons, airways in the lungs, ducts in the liver, the intestine, placenta,
cell membranes, and energy levels in proteins. They also appear in the dimension of time,
such as voltages across the cell membrane, timing of the opening and closing of
ion channels, heartbeats, and volume of breaths.[15]
Bernard’s faith in single numerical values by
objective observers is uprooted again.
The particular scale of observation chosen by the observer affects the
measurement. Despite this knowledge, we
regularly accept statements such as “the length of the coast of
Media Driven Medicine
Challenges to
our health care system are just from scientific
discourse and discoveries of
new technology. There is an active “antiscience” community
which challenges scientific facts, not on the basis of experimentation and
proof, but underlying belief systems.
For example, many believe that 60 hz powerline
emissions cause cancer, despite scientific evidence to the contrary. Parents will take their children out of
schools near powerlines out of fear that they cause cancer. The extra distance their children travel each
day is a very real risk to their health, yet they choose to expose them to this
rather in hopes of avoiding an imaginary one.
The White House Science Office estimates that the total cost of the
power line scare, including relocating power lines and lost property
value to be $25 billion,[16]
none of which is supported by scientific research.
Antiscience can be driven by the media. For example, Nobel Laureate Irving Langmuir
examined the experimental procedures of parapsychologist R.J. Rhine. He discovered that
Even where there is clear, precise scientific
information available, communicating this information to patients and providers
in the context of media-driven medicine will become increasingly difficult.
Direct to Consumer
Advertising
Drug companies are well aware of the
effects of media on the driving public
demand. Direct to consumer
(DTC) advertising has proven to be a very effective
method for drug companies to sell more of their products. Given the cost of developing new drugs, there
will be increasing pressure for these companies to increase their DTC
advertising, further driving the media-driven medicine loop. For example, in the weeks after the September
11 attacks and anthrax scare, CNN advertised an offer for a 30
day free supply of Prozac, available via
the WebMD web site. This media loop is
based on information flows entirely independent of the traditional medical
information domain, yet it is a very significant driver of health care
activities. The
information infrastructure of tomorrow must be able to accept and interact with
a much broader range of issues, which happen in “internet time” scales, not
decades.
Paths Towards Adaptive Systems
One of the most common health decisions in our
society occurs perhaps 1 million times each morning – children complaining to
their parents that they are “too sick to go to school.” Parents must sort through a plethora of vague
complaints about stomach aches, headaches, tiredness, and nausea. They consider the children’s history of
complaints, events at school, and the veracity of their claims. They must come to a decision, “Is this child
sick?”
Having access to millions of medical
terms, even if they had perfect knowledge of medicine, would not necessarily
make the decision easier. They must deal
with a coarse-grained distinction, what may be called “a crude look at the
whole.”
This term is used by Dr. Murray
Gell-Mann, Nobel laureate for his work in physics and the discovery of the
quark. He has focused in recent years on
the issues of complexity and scientific thought, and was one of the founders of
the Santa Fe Institute, in part as a “rebellion against the excesses of
reductionism.”[18] Rather than viewing a system strictly as a
hierarchy of components-within-components, he explains an alternative form of
self-organization:
“Scientists, including
many members of the Santa Fe Institute family, are trying hard to understand
the ways in which structures arise without the imposition of special
requirements from the outside. In an
astonishing variety of contexts, apparently complex structures or behaviors
emerge from systems characterized by very simple rules. These systems are said to be self-organized
and their properties are said to be emergent.
The grandest example is the universe itself, the full complexity of
which emerges from simple rules plus the operation of chance.”[19]
This approach to complex systems
thinking perhaps offers an alternative to exploding levels of complexity. Rather than trying to understand healthcare
as an exploding catalog of emergent properties, we could uncover simpler order
which are the generators of the multiplicities which become apparent in the
taxonomies.
The conductor’s score could be
considered to be a “crude look at the whole” of the music being played by an
orchestra. The language is a compact
representation of the complex interaction between conductor, musicians, musical
instruments, and the auditorium.
We do not currently have a language
which describes the biology of life at the same level of simplicity and compactness
as a conductor’s score. We can, however, do a
thought experiment. If such a language
were to exist, what
might it look like? Are
our scientific data that we are collecting today like the scientists in the
auditorium collecting ever-increasing volumes of sound waves? Is there a “score”
somewhere waiting to be discovered which would explain with great simplicity
the multiplicity of things we now see as separate, independent facts and
data? In the same way that
Computer simulations and
computational biology are exploring some of these issues:
“We
also know that agents that exist on one level of understanding are very
different from agents on another level: cells are not organs, organs are not
animals, and animals are not species.
Yet surprisingly the interactions on one level of understanding are
often very similar to the interactions on other levels. How so? Consider the following:
·
Why do we find
self-similar structure in biology, such as trees, ferns, leaves, and
twigs? How does this relate to the
self-similarity found in inanimate objects such as snowflakes, mountains, and
clouds? Is there some way of
generalizing the notion of self-similarity to account for both types of
phenomena?
·
Is there a common
reason why it’s hard to predict the stock market and also hard to predict the
weather? Is unpredictability due to
limited knowledge or is it somehow inherent in these systems?
·
How do collectives
such as ant colonies, human brains, and economic markets self-organize to
create enormously complex behavior that is much richer than the behavior of the
individual component units?
·
What is the
relationship between evolution, learning, and adaptation found in social
systems? Is adaptation unique to
biological systems? What is the
relationship between an adaptive system and its environment?
The answer to all these questions are apparently
related to one simple fact: Nature is frugal.
Of all the possible rules that could apparently be used to govern the
interactions among agents, scientists are finding that nature often uses the
simplest. More than that, the same rules
are repeatedly used in very different places:
·
Collections,
Multiplicity, and Parallelism
·
Iteration, Recursion,
and Feedback
·
Adaptation, Learning,
Evolution”[20]
Of
particular interest is Flake’s comments about the
places in which he finds universal rules of nature:
Collections, Multiplicity, and Parallelism, Iteration,
Recursion, Feedback, Adaptation,
Learning, Evolution. The describe features which are most
difficult to describe within today’s standard database framework, the
relational database.
Relational
data base technology assumes a standard form of data layout, into well-defined two
dimensional tables with specified rows and
columns. The meaning
of a datum is closely related to its structural position within the table. Databases are designed by “pigeonholing” data
elements into tables, and relationships are expressed between the pigeonholes
through additional tables. These
restrictions on freedom of expression allows the
relational calculus to be used,
but this comes at the cost of allowing individual
data elements to have properties and characteristics which are
not shared by other column “mates” in the structure.
Appendix
B presents some illustrations of how a higher level language can be
used to describe complex growth and adaptation issues.
Pigeonholing
medical information into relational data structures, therefore, inhibits it
ability to express the universal rules which Flake mentions above.
Conclusion
Just as our symphony scientists were
overwhelmed with data from their expanding array of microphones in the
auditorium, our health care system faces the risk of being overwhelmed with a
deluge of data in quantities and
forms which our current information systems can record, but not
comprehend. And just as the conductor’s
score provided a powerful, concise shorthand for understanding the symphony,
our information technology must be used to express higher level languages and
definitions of the patterns, adaptation, learning, evolution, and feedback
mechanisms of health and medicine.
Appendix A: An Example of Biological Patterns
One set of patterns
which may point to a higher level of language has been
described by Nobel Laureate Gerald Edelman,
who writes on the issue of degeneracy and complexity
in biological systems. Degeneracy, in his
paper describes the ability of elements
that are structurally different to perform the same function or yield the same
output:
Despite
the fact the biological examples of degeneracy abound, the concept has not been
fully incorporated into biological thinking.
We suspect that this is because of the lack of a general evolutionary
framework for the concept and absence, until recently, of a theoretical
analysis.[21]
He goes on to discuss
the occurrence of degeneracy as occurring at many different scales:
·
Genetic code (many
different nucleotide sequences encode a polypeptide)
·
Protein fold
(different polypeptides can fold to be structurally and functionally
equivalent)
·
Units of transcription
(degenerate initiation, termination, and splicing sites give rise to
functionally equivalent mRNA molecules)
·
Genes (functionally
equivalent alleles, duplications, paralogs, etc, all exist)
·
Gene regulatory
sequences (there are degenerate gene elements in promoters, enhancers,
silencers, etc.)
·
Gene control elements
(degenerate sets of transcription factors can generate similar patterns of gene
expression)
·
Posttranscriptional
processing (degenerate mechanisms occur in mRNA processing, translocation,
translation, and degradation)
·
Protein functions
(overlapping binding functions and similar catalytic specificities are seen,
and ‘‘moonlighting’’ occurs)
·
Metabolism (multiple,
parallel biosynthetic and catabolic pathways exist)
·
Food sources and end
products (an enormous variety of diets are nutritionally equivalent)
·
Subcellular
localization (degenerate mechanisms transport cell constituents and anchor them
to appropriate compartments)
·
Subcellular organelles
(there is a heterogeneous population of mitochondria, ribosomes, and other
organelles in every cell)
·
Cells within tissues
(no individual differentiated cell is uniquely indispensable)
·
Intra- and
intercellular signaling (parallel and converging pathways of various hormones,
growth factors, second messengers, etc., transmit degenerate signals)
·
Pathways of organismal
development (development often can occur normally in the absence of usual
cells, substrates, or signaling molecules)
·
Immune responses
(populations of antibodies and other antigen-recognition molecules are
degenerate)
·
Connectivity in neural
networks (there is enormous degeneracy in local circuitry, long-range
connections, and neural dynamics) , are all degenerate)
·
Sensory modalities (information
obtained by any one modality often overlaps that obtained by others)
·
Body movements (many
different patterns of muscle contraction yield equivalent outcomes)
·
Behavioral repertoires
(many steps in stereotypic feeding, mating, or other social behaviors are
either dispensable or substitutable)
·
Interanimal
communication (there are large and sometimes nearly infinite numbers of ways to
transmit the same message, a situation most obvious in language)
Edelman is noting the
existence of a continuum of scale, coupled with scale-independent
characteristics. This
phenomenon has been discussed earlier
in this sequence of papers,
calling the scale-independent properties
intrinsics.[22] Edelman’s work touches on notions of
fractals, characteristic scale, and a general “framework” for dealing with
complexity in biological systems.
Appendix B: L-Systems
If
there were a “score” which
could simplify our understanding,
what might it look like? One
glimpse of such a language was invented by Lindemeyer
[23] to
describe plant morphology. This
language can be examined as a model for other, more powerful languages which
express the dynamics of
growth, feedback, and adaptation
in living things.
He created a concise language which
describes a plant as an iterated sequence of segments, created according to a
production grammar. A formal description
is:
L-System A
method of constructing a fractal that is also
a model for plant
growth. L-systems use an axiom as a starting string and iteratively apply a
set of parallel string
substitution rules to yield one long string that can be used as instructions
for drawing the fractal. One method of interpreting the resulting string is as
an instruction to a turtle graphics
plotter.[24]
The following table illustrates how
an image of a tree can be drawn with progressively greater detail:
|
|
|
|
Depth =1 |
Depth=2 |
|
|
|
|
Depth=3 |
Depth=4 |
|
|
|
|
Depth=5 |
Depth=6 |






These trees are
generated by the L-Systems rule:
f=|[5+f][7-f]-|[4+f][6-f]-|[3+f][5-f]-|f
The difference between the images is the depth of
the application of the rule. Where
depth=1, the tree appears to be just twigs. This is the basic pattern of the tree, which
is used in successive depths. Each
segment of the tree for depth=1 has
been replaced with a smaller version of the basic pattern for
depth=2. Each
succeeding layer of depth repeats this
process.
This approach to expressing plant morphology has
several interesting properties.
1.
A simple formula, only 37
characters long, is able to describe the shape of the
tree.
2.
The formula stays the same,
even at different levels of detail. The
complexity of the figure drawn stays the same, only
the depth of drawing changes. Thus, an
apparently complex tree structure (depth = 5) is really just a simple structure
drawn to a greater depth.
3.
If we were to try to understand the tree by
cataloging and studying each twig, the number of points
to be studied becomes greater by about a factor of ten per depth.
4.
Looking at the expression at a lower depth allows
us a “crude look at the whole” while iterating more
deeply allows us to see greater detail.
Some examples of how L-Systems can be used to
describe complex objects can be found across the web:
An example of an L-systems growth of
a plant may be found at:
http://www.cpsc.ucalgary.ca/projects/bmv/vmm/QT/Greenash/fullview.qt
Understanding L-Systems is possibly best viewed
graphically. An interactive L-system program can be viewed at http://mitpress.mit.edu/books/FLAOH/cbnhtml/java.html

L-systems
can be used to illustrate adaptation between multiple growing
things:
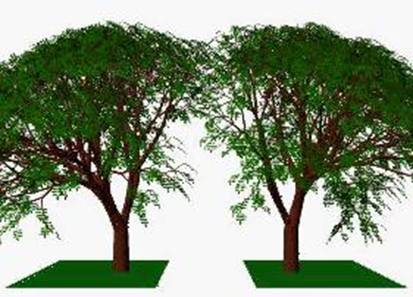
This
computer simulation shows two L-Systems
generated trees which
grow next
to each other, competing for space, illustrating the process of adaptation.

This simulation shows trees competing for
both light and space…[26]

The above drawing illustrates how L-Systems can
draw spiral phylotaxis in plants. [27]
{kind=link}
{kind=link}